
translated by Kynd and Naoto Hieda
CNNまたはconvnetとも略される畳み込みニューラルネットワークは深層学習の要であり、近年ニューラルネットワークの研究を牽引する最も突出した存在として頭角を表しています。コンピュータビジョンに革命を起こし、多くの基本的なタスクで最高レベルの結果を出し、また自然言語解析、音認識、強化学習、その他の様々な分野を大きく発展させました。テック企業は私たちが今日目にする沢山のサービスや機能のために畳み込みニューラルネットワークを用いています。下記の例のように、幅広い応用例があります。
- 画像に含まれる物、場所、人などを検知しラベル付けする。
- 人の音声をテキストに変換する。自然な音や音声を合成する。
- 画像やビデオに自然言語で注釈を付ける。
- 自動運転車で道路を把握したり周囲の障害物を避ける。
- 自動プレイの為テレビゲームの画面解析を行う。
- 「幻覚を見るように」画像、音、テキストなどを自動生成するモデルで使われる
畳み込みニューラルネットワークは初期の神経科学の研究に端を発し、(少なくとも現代の形としては)1980年代から存在しますが、複数の領域の重要な課題において並外れた成功を納め、幅広い研究者のコミュニティで認められるようになったのはごく最近のことです。畳み込みニューラルネットワークは、従来のニューラルネットワークに新しい種類の層を導入し、異なる位置や大きさ、視点に対応する能力を向上させるように拡張されています。さらにネットワークは、数十から数百のより深い層を持つようになり、画像や音声、ゲームの盤面やその他の空間的なデータ構造の階層的なモデルを作ることができるようになりました。
畳み込みニューラルネットワークは視覚関連のタスクで成功を収めたことで、クリエイティブテクノロジストやインタラクションデザイナーによって採用されるようになりました。。様々なインスタレーションの中で、動きを検知するだけでなく、物理的な空間にある物を能動的に検知・説明・追跡するために用いられています。最初にメディアアーティストの注目を集めたニューラルネットワークの応用例となるディープドリーム(Deepdream)とスタイルトランスファーを支えるのもこの技術です。
この後のいくつかの章では畳み込みニューラルネットワークに注目します。本章ではその定義と仕組みについて系統立てて説明し、次の章ではその性質について、続く章ではアートやクリエイティブな分野での応用例を扱います。
通常のニューラルネットワークの弱点
畳み込みニューラルネットワークの革新性を理解するには、「ニューラルネットワークの中をのぞく」で詳細に説明した通常のニューラルネットワークの弱点について考えることが役立ちます。
通常の1層のニューラルネットワークを訓練した際に、入力されたピクセルと出力ニューロンの間の重みがそれぞれの出力クラスのテンプレートに見えるようになったことを思い出してください。これはそれぞれのクラスについての全ての情報を1つのレイヤーで捉えるように制限されていたからです。テンプレートはそれぞれ、そのクラスに属する画像の平均を取ったように見えます。

MNISTのデータセットではこのテンプレートは比較的判別しやすく効果的でした。しかし同じように訓練を行ってもCIFAR-10の結果はずっと認識しづらいものになってしまいます。この原因はCIFAR-10がMNISTに比べてずっと多くのバラつきを含んでいることです。例えばイヌの画像では、イヌが丸まってたり、伸びをしていたり、毛の色が違ったり、他の物が散らばっていたり、その他の様々な邪魔が入っていることがあります。これら全てのバリエーションを1層だけで学習するよう無理をした結果、ネットワークは全ての犬の画像の平均を取るのと変わらない貧弱な仕事しかできず、初めて見る画像を正確に安定して見分けることはできなくなってしまいます。
隠れ層を足し、ネットワークが見つけた特徴の階層を組み立られるようにすると、この問題に対抗することができます。例えば、(以前と同じように)MINIST用に10個のニューロンからなる隠れ層と、10個の数字に対応した10個の出力ニューロンを含む、2層のネットワークを作ることを考えてみましょう。重みを導き出すために訓練を行います。下の図では最初の層の重みを以前と同じ方法で可視化しています。また、併せて10個の隠れ層のニューロンを10個の出力ニューロンにつなぐ2層目の重みを棒グラフで示しました(簡単にするため、最初の2つのクラスの分だけを示しています)。

1層目の重みは以前と同じように可視化できますが、数字というよりはその断片、もしくは全ての数字ごとに違う度合いで現れる、より一般化された形やパターンのように見えます。棒グラフの1段目は、数字の0を識別する出力ニューロンに対してそれぞれの隠れ層のニューロンがどれだけ影響するかを示しています。1層目のニューロンのうち、外側に輪のような形を持つニューロンが好まれ、中央部分に高い重みを持つニューロンが嫌われていることが分かります。2段目は1を識別するニューロンに対して同じ可視化を行ったもので、中央部分に対して高い値を持つ画像に対して強く反応する隠れ層のニューロンが好まれています。このことからネットワークは一層目で、手書き文字の中である数字には含まれてそれ以外には含まれないような、漠然とした特徴を学習することがわかるでしょう。例えば外側のループは8や0にはよく当てはまりますが、1や7には当てはまりません。画像中央の斜めのストロークは8や2に当てはまりますが、5や0には当てはまらず、右上の急カーブは2や7、9に有効ですが5や6に対してはそうではありません。
CIFER-10にも関連した例があります。馬の画像の多くは左向きや右向きの馬で、それらを元にテンプレートを作るとぼんやりとした2本の首がある馬のようになってしまいます。隠れ層がある場合には、ネットワークは「左向きの馬」と「右向きの馬」のテンプレートを隠れ層で学び、出力ニューロンはそれぞれに対して強い重みを割り当てられる可能性があります。これは特にエレガントな改善ではありませんが、規模が増すにつれ、この戦略がどのようにネットワークをより柔軟にしてくれるかを見て取ることができます。初めの方の層はより局所的で一般に適用可能な特徴を学び、後の層はそれらを組み合わせることができます。
こうした改善にも関わらず、多様な画像のデータセットの全てを特徴付けるほぼ無限の組合せをネットワークが記憶するのは実用的ではありません。それほどの情報を捉えようとすると現実に記録したり訓練するには多すぎる数のニューロンが必要になるでしょう。畳み込みニューラルネットワークの利点は無数の特徴の組み合わせををより効率的に捉えられるようにすることです。
構成性
訳注:構成性(Compositionality)とは、複雑な表現の意味は、それを構成する部分的な表現の意味と、部分をつなぎ合わせる規則によって決まる、という考え方のことです(出典:英語版ウィキペディアから抄訳)。
どうしたら数多くのクラスに含まれる多様な画像を効率よくネットワークを用いて表現することできるでしょうか。例を用いて考えることでこの疑問に対する直感が得られるでしょう。
あなたにいままで見たことのない車の写真を見せたとします。きっとあなたは車の様々な特徴が並んでいることに気づき、それを車だと識別できるでしょう。言い換えれば、その写真はフロントガラス、ホイール、ドア、排気管など、ほとんどの車を構成するパーツの組み合わせを含んでいます。この写真と全く同じパーツの組み合わせには出会ったことがないにもかかわらず、それぞれの小さなパーツを認識して足し合わせることであなたはそれが車の写真であることに気づきます。
畳み込みニューラルネットワークはこれに似たことを試みます。対象物の個々の部分を学習して個々のニューロンに記録し、それらを足し合わせてより大きな物体を認識します。このアプローチには2つの利点があります。まず、特定の物についてより少ない数のニューロンでより多くの種類を捉えられることです。例えば10個のテンプレートで異なる種類のホイールを覚え、ドアとフロントガラスについてもそれぞれ10のテンプレートを用いたとしましょう。30個のテンプレートを使って $10 \times 10 \times 10 = 1000$ 種類の車を捉えることができます。これは内部にたくさんの重複を抱えた約1000個の異なるテンプレートを保持するよりもはるかに効率的です。更に、これらの小さなテンプレートは異なる物のクラスにも再利用できます。ワゴン車にもホイールがあります。家にもドアがあります。船にもフロントガラスがあります。より多くの物のクラスの集まりを小さな部品の様々な組み合わせで構築でき、しかもとても効率的に行えます。
畳み込みニューラルネットワークの歴史と先行研究
畳み込みニューラルネットワークがこれらの種類の特徴を検出する方法を順を追って見ていく前に、ここまで述べてきた問題に対して畳み込みニューラルネットワークがどのように進化してきたか理解する為、先行する重要な研究を紹介しましょう。
ヒューベルとウィーセルの実験(1960年代)
1960年代に動物の視覚野の特性を調べるため、神経生理学者のデイヴィッド・ヒューベルとトルステン・ウィーセルが一連の実験を行いました。彼らは最も特筆すべき実験の1つにおいて、テレビスクリーンのシンプルなパターンで猫の脳を刺激してその電気反応を測定し、視覚野の初期段階におけるニューロンが次のように階層的に組織されていることを突き止めました。まず、猫の網膜につながっている最初のセルはエッジやバーといったシンプルなパターンの検出を担っており、後の層がそれら初期階層のニューロンの出力を組み合わせることでより複雑なパターンを検出するのです。
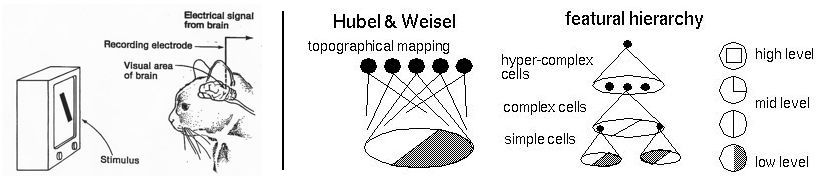
後のマカクザルの実験でも似た構造が見つかり、新しい分野である哺乳類の視覚処理の理解がより洗練されていきました。彼らの実験は、明確に定義されたコンピュータビジョンの計算フレームワークの構築を目指している人工知能の研究者たちに、きっかけとなるインスピレーションを与えました。
福島のネオコグニトロン(1982)
ヒューベルとウィーセルの実験は、福島邦彦がニューラルネットワークで視覚野の階層的で構成的な視覚野の仕組みを模すことを試みたネオコグニトロンを考案した際に、インスピレーションとして直接言及されています。ネオコグニトロンはスライディングウィンドウを用いることで、階層になったそれぞれの層が前の層から画像の中の位置に関わらずパターンを検出することのできる構造を持った初めてのネットワークでした。
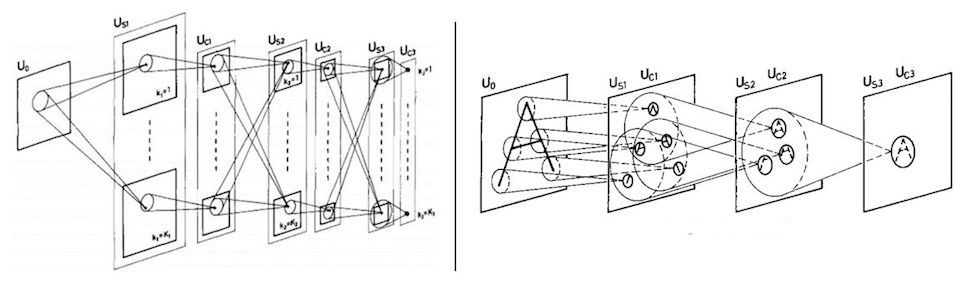
ネオコグニトロンはパターン認識においてある程度の成果を納め、畳み込みフィルターをニューラルネットワークに取り入れたものの、フィルター自体を学習するアルゴリズムを欠いていたために限界がありました。パターン検出器は特定の役割のために、人の手によってコンピュータビジョンの経験則や技術を用いて設計されていたのです。当時バックプロパゲーションはまだニューラルネットワークでは用いられておらず、ネオコグニトロンを異なる視覚認識の目的に再利用する簡単な方法はありませんでした。
LeNet (1998)
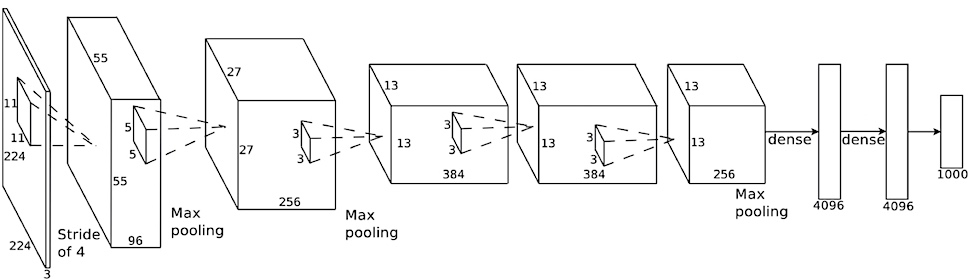
1980年代後半にGeoffrey Hintonら が初めてバックプロパゲーションをニューラルネットワークの訓練に応用することに成功しました。90年代の間、Hintonの研究員だった Yann LeCun が率いるAT&T Labsのチーム が“LeNet”の愛称をもつ畳み込みネットワークを訓練し、手書きの数字を99.3%の精度で判別できるようになりました。彼らのシステムは一時期、アメリカで発行された小切手の10%から20%を自動判別するのに使われました。LeNetは7層あり、そのうち2層は下に図で示したような畳み込み層でした。
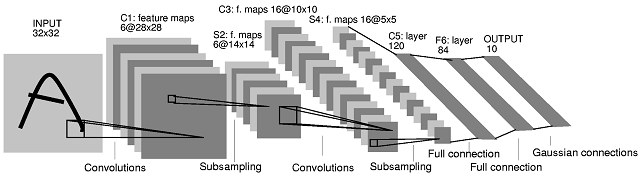
彼らのシステムは産業レベルで応用された初めての畳み込みネットワークでした。この大成功にも関わらず、ニューラルネットワークをより多くのクラスを識別する仕事や、より高解像度、またはより複雑な対象に対して拡張することはできないと多くのコンピュータサイエンティストは思い込んでいました。そのため、10年以上の間ほとんどのコンピュータビジョンの課題には他のアルゴリズムが使われ続けていました。
AlexNet (2012)
2010年代前半、畳み込みネットワークはコンピュータビジョン、更にはより一般的な機械学習のアルゴリズムにもとって代わるようなりました。2009年にはプリンストン大学のコンピュータサイエンス学部のFei-Fei Li率いる研究者らが、Mechanical Turkを用いて手動で1000個のクラスにラベル付けされた1400万枚以上の画像を含む大規模なデータセット、ImageNetデータベースを取りまとめました。ImageNetはこれまでにリリースされた同種のデータセットの中では最大で、すぐに研究コミュニティの必需品となりました。翌年にはImageNetを使うコンピュータビジョンの研究者を対象とした年に一度の大会、ImageNet Large Scale Visual Recognition Challenge (ILSVRC)が始まりました。ILSVRCは重要なベンチマークである画像の認識、分類、位置検出などの精度を競う研究者たちを迎え入れました。これらの課題については本章でより詳細に説明します。
大会が始まって2年の間、全ての優勝者は当時の標準的なコンピュータビジョンの手法を使っており、畳み込みネットワークは用いられていませんでした。画像分類のトップ5エラー(上位5つの予想がすべて外れている)は25~28%でした。2012年にトロント大学のGeoffrey HintonとIlya Sutskever、Alex Krizhevskyの率いるチームが「AlexNet」という愛称を持つdeep convolutional neural networkを提出し、40%以上の劇的な差をつけて優勝しました。AlexNetは画像分類のトップ5エラーの以前の記録である26%を破り15%としました。
その翌年からILSVRCのエントリーほぼ全てが畳み込み層を持つディープニューラルネットワークを用いており、前回ILSVRCが開催された2017年には分類誤差は約2%まで急降下を続けました。今では畳み込みネットワークはImageNetの画像分類において人間よりも優れています!これらの記念碑的な成果は今後のディープラーニングに対する期待を強く煽ることとなり、コンピュータビジョンの先行きに革命をもたらしたと多くの人々によって考えられています。更に、residual layersなど、現在のネットワーク構造で一般的に用いられている重要な革新的な研究の多くは、ILSVRCへのエントリーとして登場しました。
畳み込み層の仕組み
固有の名前がついていても、畳み込みネットワークとこれまでに見てきたニューラルネットワークが全くの別物という訳ではありません。畳み込みネットワークは、以前のネットワークの機能の多くを継承した上で、畳み込み層と呼ばれる新しい種類の層を中心に、ネオコグニトロンが取り入れた新しいアイデアを模したり改善したいくつかのイノベーションを導入し改善したものです。畳み込み層を少なくとも1つ持ったニューラルネットワークは、畳み込みネットワークと呼ぶことができます。
フィルターと特徴マップ
これまでの章では全結合層、つまりそれぞれのニューロンが前の層のニューロン全てと繋がっている層だけを扱ってきました。これは畳み込み層には当てはまりません。数学的には畳み込み層は全結合層ととてもよく似ていて、違うのはその構造だけです。まず、全結合層ではニューロンの値 $z$ を前の層のニューロンの重み付き和、$z=b+\sum{w x}$ として計算することを思い出しましょう。
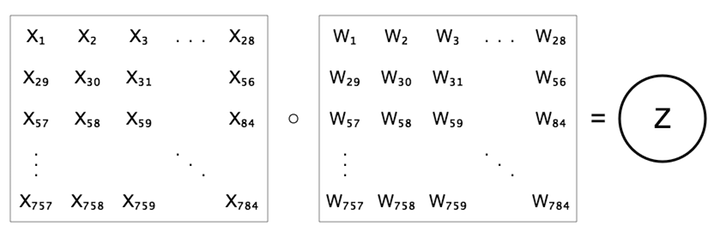
この重みの集合は、特定の特徴が存在するかどうかを調べる特徴検出器だと考えられます。以前にMNISTやCIFARに対して行ったように、これらの検出器を視覚化することができます。1層の全結合層では、この「特徴」は単に画像のクラスそのものなので、重みの配列はまるでそのクラス全体のテンプレートのように見えました。
畳み込み層では代わりに畳み込みフィルターと呼ばれる小さな特徴検出器の集まりが用いられます。個々の畳み込みフィルターは画像全体の上をスライドしながら、これまでと同じく重み付き和の計算を画像の部分ごとに行ないます。そして小さなフィルターそれぞれに対して、画像のどこに特徴が存在するかという反応の強さを示した特徴マップを作り出します。
下のインタラクティブなデモで、フィルターが画像の畳み込みを行うプロセスを見ることができます。
このデモはMNISTの数字の上に1層の畳み込み層を表示します。このネットワークの層にはちょうど8個のフィルターがあります。その下にはそれぞれに対応した8つの特徴マップを示します。
特徴マップのピクセルそれぞれが、ネットワークの次の層のニューロン1つに当たると考えられます。この例には $25 \times 25$ ピクセルのマップを作り出す8個の層があるため、次の層には $8 \times 25 \times 25 = 5000$ 個のニューロンがあることになります。それぞれのニューロンは、特定のxy座標にある特徴が存在する度合いを表しています。これまでに見てきた可視化の方法と今回との違いを強調しておきましょう。前章までではずっと、通常のニューラルネットワークのニューロン(とその反応)を1つの長い列として見てきましたが、今回は特徴マップの集まりとして見ています。1列に引き延ばすこともできますが、この方法で可視化した方が何が起きているのかを視覚的に把握できるので便利でしょう。この点については後の節で改善します。
畳み込み層には事前に設定する必要があるいくつかの属性、つまりハイパーパラメータがあります。これには深度(フィルターの数)、フィルターのサイズ(上の例では $5 \times 5$)、ストライド(フィルターをずらしていく際の距離)、パディング(特徴マップの周辺を特定の値で埋めること)などがあります。これら全てを説明するのはこの章の範囲外ですが、ここ(英語)で概要を得ることできます。
プーリング層
畳み込み層の重要性を説明する前に(ずっとシンプルな)別の種類の層で、畳み込み層のすぐ後で非常によく用いられるプーリング層について簡単に紹介します。もともとLeCunは「サブサンプリング」層と呼んでいましたが今ではプーリング層と呼ぶのが一般的です。
プーリングは、特徴マップの解像度を下げるために使われ、通常は2を係数としてダウンサンプリングします。。最も一般的な方法は隣接する $2 \times 2$ のピクセルの最大値を取って結合するmax(最大値)プーリングです。下に例を示します。
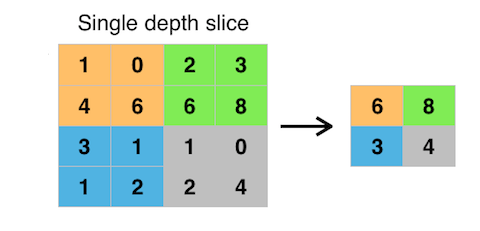
プーリングの利点はあまり情報を失うことなくデータの量を減らし、また位置のずれに対してある程度の不変性を実現できることです。またこの処理は重みなどのパラメータを学習する必要がないので非常に安価です。
最近ではプーリング層の人気は衰え始めています。いくつかのモデルでは、フィルターを1ピクセルではなく2ピクセルずつスライドさせてダウンサンプリングの処理を畳み込み層自体で行い、結果として特徴マップのサイズを半分にしています。これらの “all convolutional net”にはいくつかの重要な利点があり、より一般的になってきていますが、実際にはまだプーリング層が完全に使われなくなった訳ではありません。
ボリューム
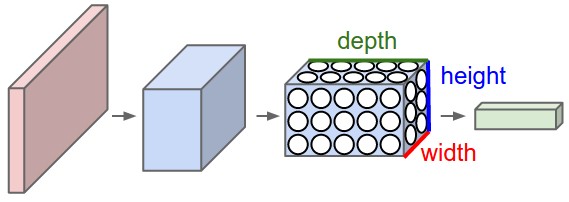
一歩引いてより広い視野で見てみましょう。ここから先に進むにあたっては、畳み込みネットワーク内に流れるデータを、例えば3次元構造を持った「ボリューム」だと考えると役に立ちます。これまでの章ではずっと、ピクセルを長いニューロンの列として視覚化してきました。しかし畳み込みネットワークを適切に視覚化するには、8つの特徴マップを持つ上のデモのように、画像の中における実際の配置のままニューロンを並べる方が理にかなっています。
この観点では画像を立体的なボリュームを持ったデータだと考えることができます。1つ前の例について考えて見ましょう。元の画像は $28 \times 28$ のグレースケール(つまり1チャンネル)でした。これは $28 \times 28 \times 1$ の大きさを持ったボリュームです。最初の層ではこの画像を $5 \times 5 \times 1$ のフィルター8つで畳み込みを行いました。結果 $24 \times 24$ の特徴マップ8つができるので、この畳み込み層からの出力は $24 \times 24 \times 8$ です。maxプーリングを行うと大きさは $12 \times 12 \times 8$ になります。
訳注:なぜ出力が $24 \times 24$ になるのかが少し分かりにくいかもしれません。横方向の28ピクセルにだけに注目してみると、5ピクセル幅のフィルターを置く方法は1〜5ピクセル目に重なった状態から1ピクセルずつスライドして、24〜28までの24通りあることが分かります。縦方向も同様なので、$28 \times 28$ の画像に $5 \times 5$ のフィルターを重ねる方法は $24 \times 24$ 通りになります。
カラー画像の場合はどうでしょう。この考え方は簡単に拡張できます。この場合畳み込み層もまたカラーなので3つのチャンネルを持ちます。畳み込みの処理はこれまでと全く同様ですが、単純に掛け算の回数が3倍になります。乗算はx方向とy方向に並列で行われますが、同時に各チャンネルに対しても行われます。$32 \times 32 \times 3$ のCIFAR-10のカラー画像を使い、$7 \times 7 \times 3$ のフィルター20個からなる畳み込み層を通すと出力のボリュームは $26 \times 26 \times 20$ になります。$7 \times 7$ のフィルターを $32 \times 32$ の画像の上に置くことができる位置は $26 \times 26$ 個あり、20個のフィルターがあるため深度は20になります。
特徴マップを重ねたものはある種の「画像」だと考えることができます。RGB画像のように3つだけではなく20チャンネルもあるので本来の意味での画像ではもちろんありませんが、表現としては同じ形をしていることに注目しましょう。入力画像のボリュームは $32 \times 32 \times 3$、畳み込み層からの出力のボリュームは $26 \times 26 \times 20$ の形をしています。$32 \times 32 \times 3$ の値は単に画像の全ピクセルについて赤、緑、青の明度を示していますが、$26 \times 26 \times 20$ の値は、それぞれのピクセルを中心とした狭い範囲に対する、20個の異なる特徴検知器の反応の強さを示しています。この2つは画像のピクセルそれぞれについての情報を与えてくれるという点で同じですが、その情報の質が異なっています。$26 \times 26 \times 20$ のボリュームは元のRGB画像から抽出されたより「高レベル」な情報を持っているのです。
更なる深みへ
さてここからが複雑です。典型的なニューラルネットワークにはしばしば複数の畳み込み層(とプーリング層)が含まれています。最初の畳み込み層の出力が $26 \times 26 \times 20$ だとして、そこにそれぞれが $5 \times 5 \times 20$ のサイズを持つ新しい特徴検知器30個からなる畳み込み層を繋げます。深度はなぜ20なのでしょう。フィルターをうまく適用するには畳み込みの対象になる特徴マップと同じ数のチャンネルが必要になるからです。パディングなしの場合、新しいフィルターはそれぞの $22 \times 22$ の特徴マップを作り出します。フィルターは30個あるので、$22 \times 22 \times 30$ のサイズを持つ新しいボリュームが得られます。
この新しい畳み込みフィルターと、結果として得られる特徴マップ、またはボリュームをどう解釈すれば良いでしょう。これらの特徴検知器はその前のボリュームに含まれるパターンを探します。既に前のレイヤーからはパターンが出力されているので、この新しいフィルターはパターンのパターンを探していると考えることができます。考えるのが難しいかもしれませんが、特徴検知器の意義から直接類推することができます。最初の検知器群が方向の異なる輪郭と行ったシンプルなパターンだけを見つけるとすれば、2つ目の検知器群はこれらのパターンを組み合わせてもう少し複雑な「高レベル」のパターン、例えば角や升目のような物を作ることができます。
3つ目の畳み込み層を追加したらどうなるでしょう。この層で見つかるパターンはより高レベルな、おそらくは複雑な格子模様や簡単な物体のようなものになります。これらの基礎になる物体を別の畳み込み層で組み合わせると更に複雑なものを検知でき、これは繰り返すことができます。特徴検知器を連続して重ねていくと、シンプルで低レベルなパターンから複雑で高レベルな物体まで階層的に組み建てて学習することができ、これがディープラーニングの核となる考え方です。最後の層では分類を行いますが、多くの層を通じて得られる高レベルの表現のおかげで、ピクセルそのものや、手入力された統計的な表現を用いるよりもずっと上手に学習できます。
どのようにフィルターが決まるのか不思議に思いますか。フィルターは単に複数の重みを集めたもので、これまでの章で扱ってきた重みと変わりがないことを思い出してください。これらの重みは訓練を通じて学習されるパラメータです。このプロセスについては 前章のニューラルネットワークの訓練を見てください。
CIFAR-10の精度を改善する
下のインタラクティブなデモでは、CIFAR-10のデータセットを判別するよう訓練され、79%とかなりの精度に達した畳み込みニューラルネットワークの混同行列を見ることができます。CIFAR-10の判別における最先端の成果はおよそ96%に達しますが、それでもクライアントサイド、CPUのみでJavascriptのライブラリだけを用いて学習した結果としては、79%は素晴らしい結果です。畳み込み層なしの通常のニューラルネットワークは37%の精度しか出せなかったことを思い出してください。畳み込み層による目覚ましい改善が見て取れます。メニューから選ぶと、畳み込みニューラルネットワークと通常のニューラルネットワークをCIFAR-10とMNISTに対して訓練した結果の混同行列を見ることができます。
畳み込みニューラルネットワークの応用
2010年代の前半から、畳み込みニューラルネットワークは最も幅広く様々な応用範囲で使われるディープラーニングのアルゴリズムとして台頭してきました。一時は一握りのコンピュータビジョンの課題でしか成功したと見なされていませんでしたが、今では音やテキスト、その他様々な種類のデータ処理で用いられています。これまで学習アルゴリズムを新しい課題に用いる際に最も時間とコストがかかっていた特徴の抽出を自動化できることが、畳み込みニューラルネットワークの汎用性を支えています。特徴の抽出が学習プロセスそのものの中に組み込まれているため、多くの場合にわずかな変更だけで既存のネットワーク構造を全く異なる課題や領域に再利用し、訓練や「ファインチューニング」を行うことが可能になりました。
訳注:ここでのファインチューニングとはネットワークを再利用する際に学習済みの重みをコピーし、さらに訓練を通じて調整を行うことを言います。既存のネットワークを似た課題に適用する、例えばImageNetで訓練したモデルを他の画像セットの識別に利用するケースでは、学習されたパターン(重み)もそのまま利用することで低コストで高い精度を得ることが期待できます。多くの場合、入力側に近い低レベルのフィルターは汎用性が高いパターンを学習しているため凍結し、出力側に近いいくつかの層を、モデルを壊してしまわないように小さめの学習率で訓練します。出力層は必要な出力クラスが異なる為、一般に差し替えになります。
数ある畳み込みニューラルネットワークの応用例を全て検討することはこの章の範囲を超えますが、この節ではクリエィティブな用途に関連があるいくつかの例を取り上げます。
コンピュータビジョン
畳み込みニューラルネットワークは画像の分類以外にも、画像についてのより具体的な情報を与えてくれるいくつかの課題について訓練することができます。画像の分類に関連が深いものとして位置の特定、つまり分類の結果、一番の主題となる物体に長方形の境界線を割り当てるという課題があります。一般的にこの課題では、分類と同時にネットワークが最も正確な長方形の座標($x$, $y$, 幅と高さ)を予想するための回帰を平行して行います。
この課題はより高度な物体検知に拡張できます。物体検知では1つの物体の分類と位置の特定だけを行うのではなく、複数の物体の位置と種類を検知します。下記の画像にこれら3つの関連する課題を示します。
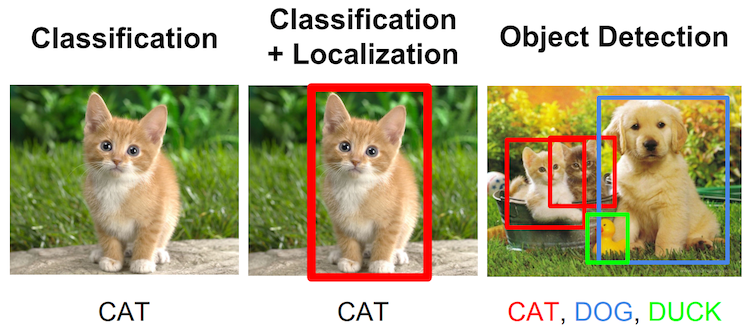
密接に関連した課題に、画像を見つかった全ての物体を切り分ける、セマンティックセグメンテーションがあります。これは物体検知に似ていますが、単なる長方形ではなく、物体の実際の境界線全体を求めます。

セマンティックセグメンテーションと物体検知は比較的最近になってやっと実現されました。単一クラスの検知に比べて複雑なだけでなく、データが手に入らないことが大きな枷となっていたのです。分類のレベルを飛躍させたImageNetのデータセットですら、物体の位置についての情報が希薄なため物体検知やセグメンテーションには役に立ちませんでした。しかし、より最近になってMS-COCOのようなデータセットがデータ構造に画像それぞれについてのより豊かな情報を追加したため、位置の特定、物体検知やセグメンテーションを本格的に追求できるようにになりました。
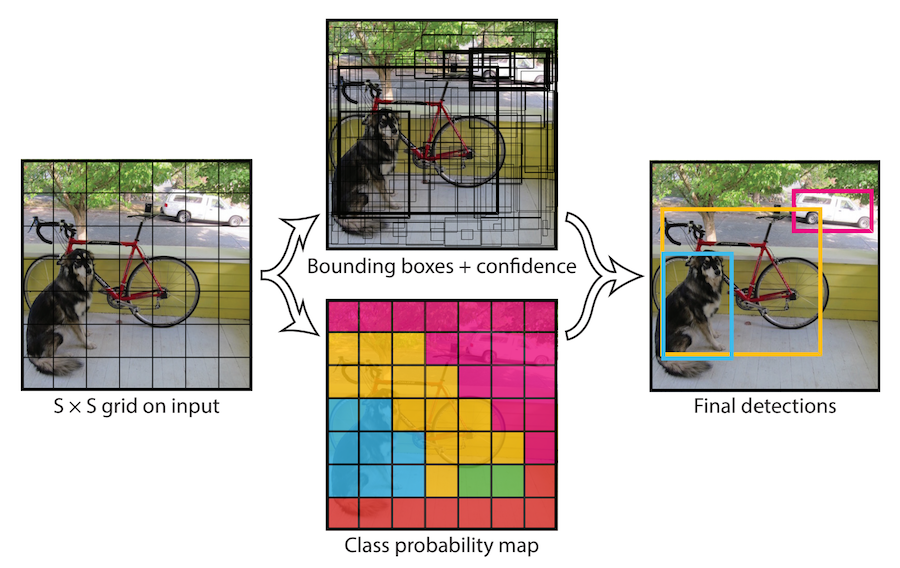
畳み込みニューラルネットワークを物体検知のために訓練する初期の試みは一般的に、可能性のある境界を特定して単純に分類をこの境界に対して行い、もっとも確度が高いものを残すことで位置を特定する方法を用いていました。しかしこのアプローチは何十何百とある候補それぞれに対して最低でも1回のフォワードパスを行わう必要がある為、とても遅いものでした。自動運転のような特定の状況では、この遅れは明らかに受け入れられません。2016年に Joseph Redmonはこの問題に対処するためYOLO を開発しました。YOLOはネットワークが画像を1回だけ「見る」ように制限する、つまり1回のフォワードパスだけでネットワークが必要な情報全てを手に入れるようにするため、”You only look once(あなたは一度だけ見る)”の頭文字をとって名付けられました。YOLOは、一定の状況で複数の物体の検知で40から90フレーム/秒の処理速度を達成し、この応答速度を必要とするリアルタイムのシナリオにも適用できるようになりました。このアプローチでは画像を同じサイズのグリッドに分割し、それぞれに対して物体検知を行って候補となる物体を予想します。最後には確度の高い領域が残されます。下の図にこのアプローチをまとめました。
訳注:さらに元を辿ればYOLOという接頭語はDrakeの”The motto”に出てくる“You only live once, that’s the motto…YOLO”というフレーズを元にしたものです。

ここ数年の間、さらにいくつかのコンピュータビジョンに関連した用途が見つかり改善されてきました。再帰を用いた畳み込みニューラルネットワーク(後の章で紹介します)により画像からテキストを取り出すために特化したシステムや、画像に自然言語で注釈を付けるものもあります。これらについては後の章で取り上げるか、「もっと読む」のリンク先に任せることにします。
音声への応用
畳み込みニューラルネットワークの最も驚くべき側面は恐らくその万能性と、音に関する領域での成功にあります。(この章も含めて)ほとんどの入門書や記事ではコンピュータビジョンに重きを置いていますが、畳み込みニューラルネットワークは音の領域でも同じくらいの間、目覚しい結果を残してきました。音声認識や、音からその他の情報を取り出す用途に使われ、この数年の間に以前までのアプローチを置き換えています。ニューラルネットワークが台頭するまでは音声からテキストへの変換は一般に隠れマルコフモデル と、従来のデジタル信号処理を用いて手動で作られた特徴抽出モデルによって行われてきました。
より最近の畳み込みニューラルネットワークの用途には2016年後半にDeepMindの研究者によって紹介されたWaveNetがあります。 WaveNetは大量の音の生データで訓練を行うことで音を合成する方法を学ぶことができます。WaveNetはMagentaによってカスタムのデジタルオーディオシンセサイザーを作る為に使われ、現在ではGoogle アシスタントの音声を作りだすために使われています。

コンピュータビジョンに関連した画像の領域、および再帰を用いた畳み込みニューラルネットワークによって(画像などの)生成を行う応用方法については後の章で取り上げます。