todo: header=dog conv filters
Visualizing weights and activations

How to excite neurons
One simple way to get a hint of the features that neurons learn is by measuring their responses to test images. We feed many images to the network, and then for a particular neuron of interest, we extract patches of those images which maximally activated it. The following figures are taken from Visualizing and Understanding Convolutional Networks by Zeiler and Fergus.

What do we see in this experiment? It seems the resulting image patches resemble the filters. For example, for the top left filter, we receive image patches with strong diagonal slopes, and in the middle filter in the bottom row, we get dark green square patches. For at least the first layer, this should make intuitive sense given what we saw in the previous chapters; the more a patch is correlated to a filter, the stronger its activation in that filter will be, relative to other patches.
But what about subsequent convolutional layers? The principle still applies, but we are currently interested in the original images, not the input volumes at those layers which get processed by the filters. By then, there has already been several layers of processing, so it doesn’t make sense to compare the filters to the original images. Nevertheless, we can still perform the same experiment at later layers; we can input many images, measure the activations at later layers, and keep track of the image patches which generate the strongest response. Note that at later layers, the effective “receptive field” for a neuron is larger than the filter itself, due to pooling and convolution in previous layers. By the last layer of the network, the receptive field has grown to encompass the entire image.

Above, we are looking at the experiment repeated at layer 2. The effective receptive field is now larger, and it no longer makes sense to compare them to the actual filters for each of those neurons. Strikingly though, we see that the image patches within each cell have much in common. For example, the cell at row 2, column 2, responds to several images that contain concentric rings, including what appears to be an eye. Similarly, row 2, column 4, has patches which contain many arcs. The last cell has hard perpendicular lines. It should be noted that these image patches often vary widely in terms of color distribution and lighting. Yet they are associated by sharing a particular feature which we can observe. This is the feature that neuron appears to be looking for.
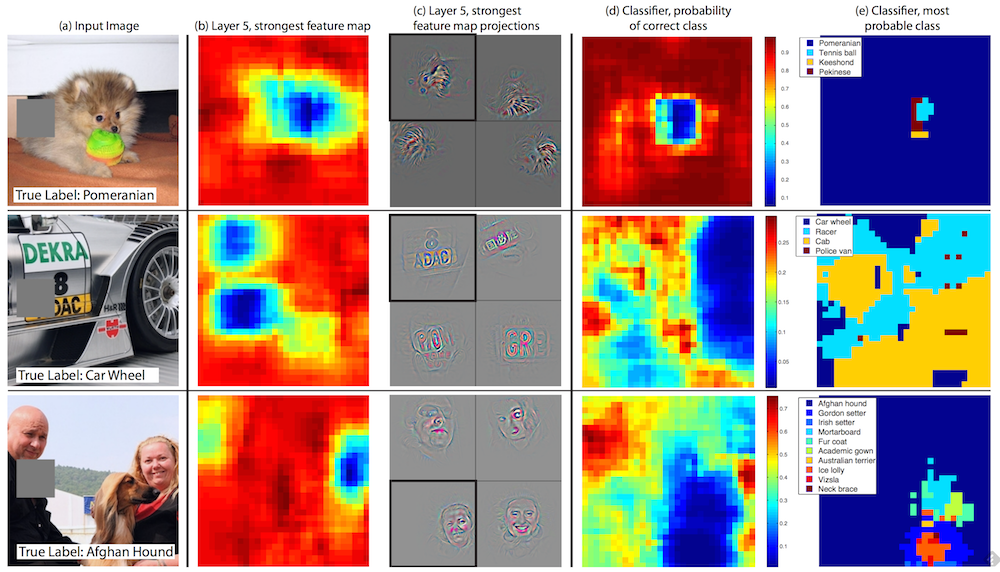
todo: zeiler/fergus visualizing what neurons learn, image ROIs which maximally activate neurons
Occlusion experiments
todo: occlusion experiments, zeiler/fergus visualizing/understanding convnets https://cs231n.github.io/understanding-cnn/
Deconv / guided backprop
todo: deconv, guided backprop, deepvis toolbox
todo: inceptionism class viz, deepdream
deconvnets http://cs.nyu.edu/~fergus/drafts/utexas2.pdf zeiler: https://www.youtube.com/watch?v=ghEmQSxT6tw Saliency Maps and Guided Backpropagation on Lasagne https://github.com/Lasagne/Recipes/blob/master/examples/Saliency%20Maps%20and%20Guided%20Backpropagation.ipynb multifaceted feature vis https://arxiv.org/pdf/1602.03616v1.pdf

Visualizing
aubun visualizing lenet classes http://www.auduno.com/2015/07/29/visualizing-googlenet-classes/ peeking inside convnets http://www.auduno.com/2016/06/18/peeking-inside-convnets/
Neural nets are easily fooled
http://www.evolvingai.org/fooling + https://arxiv.org/pdf/1412.1897.pdf https://arxiv.org/pdf/1412.6572v3.pdf https://karpathy.github.io/2015/03/30/breaking-convnets/
todo: neural nets are easily fooled https://arxiv.org/abs/1412.1897
todo: ... but not on video
Etc
todo: notes on performance
todo: attention, localization
Hint
Google cat -> deepdream
Further reading
https://cs231n.github.io/understanding-cnn/
keras how convnets see the world https://blog.keras.io/how-convolutional-neural-networks-see-the-world.html
http://yosinski.com/deepvis https://www.youtube.com/watch?v=AgkfIQ4IGaM
https://youtu.be/XTbLOjVF-y4?t=12m48s
https://jacobgil.github.io/deeplearning/class-activation-maps
http://arxiv.org/pdf/1312.6034v2.pdf
http://arxiv.org/pdf/1602.03616v1.pdf