What is it?
ConvnetPredictor is an openFrameworks application, part of the ml4a-ofx collection, which lets you train a neural network to control one or more continuous variables (sliders) with your webcam. The app learns a regression to predict the slider values, from a set of example input/output pairs collected via webcam stream. It is closely related to ConvnetClassifier, which is the same as ConvnetRegressor, except that it does classification over discrete categories rather than continuous variables.
todo: ableton time trial
Training instructions
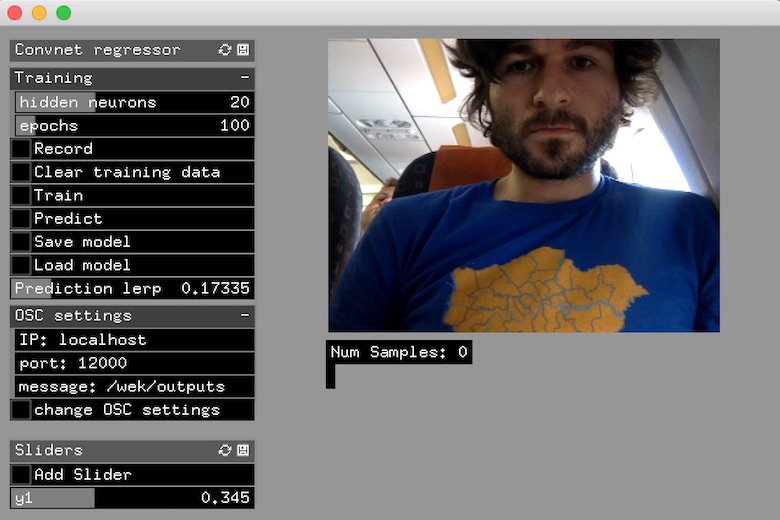
-
One slider is loaded by default. Click ‘add slider’ if you wish to train more.
-
Set the sliders to a particular set of values, and then click ‘record’ to begin recording images from the webcam. The images are analyzed by a convnet, and the feature vector extracted becomes associated with the set of slider values set.
-
Repeat #2 for as many sets of values as you wish.
-
Set training parameters,
hidden neuronsandepochs(training iterations). In general, the higher these are, the more accurate the training will be, but the longer it will take. -
Click train, and wait. Enjoy the flashing colors.
-
Once trained, toggle
Predictto have the sliders get set by the trained network. -
The slider
prediction lerpto control the amount of easing in the predicted slider values. If set to 1.0, there is no easing, and the sliders are set to the predicted value exactly (this may be erratic). If set to a lower value, the sliders will fluctuate more gradually.
OSC Output
The OSC destination (IP address and port), and the message to bind the prediction values can be set by clicking ‘Change OSC settings’. All settings are saved on exit, and will be loaded back next time you open the application.
Setup and training considerations
ConvnetRegressor is a very versatile application that can be used in a wide variety of setups. However, to optimize accuracy, some simple rules of thumbs are:
-
Ensure variety in your training data: Say you want to associate a set of sliders with someone holding an object in their hands; try to record training samples that shows the person holding the object in different postures and positions, close to the camera, far from the camera, in both hands etc.
-
Keep your settings stable when using small training samples: Training in different sets of lighting conditions and hereafter attempting to classify in yet another environment might prove difficult. The same is true for camera positions and angles, backgrounds, etc. Unless you intentionally want a regressor that is can handle different settings (which would require more training examples), you can save yourself a lot of sweat by keeping your physical setup stable.
-
If the regression is not accurate enough, try to record more training examples, or train for more epochs or with more neurons in the hidden layer. Alternatively you can try different classifier algorithms, which can be set in the setup() function of ofApp.cpp.